



添加时间:2024-04-22 14:20:52
在自然语言处理工作(NLP)中,会遇到这样的一个应用问题:如何挖掘文本中某一关键词的语义相似词或近义词?解决该问题的办法很多,比如使用近义词词库进行匹配,或检索词语类的知识库(HowNet),也可用word2vec之类的词向量技术进行cosine相似计算。再高级点,可利用像BERT之类的预训练模型进行预测,但这种方式对中文词不太友好。此外,上述的挖掘方法都存在一个共同的缺陷,都没考虑关键词所在的语义环境。
针对上述场景,今天分享一篇基于上下文语义来挖掘相似词或近义词的paper,论文为《CASE: Context-Aware Semantic Expansion》,论文题目的意思为基于上下文感知的语义扩充,解决的场景如下图。如要挖掘句子中与“氨基酸”(amino acid)相似的语义词,若不考虑语义环境,与之匹配的有维生素(vitamin)、抗氧化剂(antioxidant)、脂肪(fat)等等;但若考虑文本语义,脂肪不能作为氨基酸扩充的语义词,因为青稞草(amino acid)不富含脂肪,这在语料库中也不会有类似的描述。

paper先定义如下学习任务:
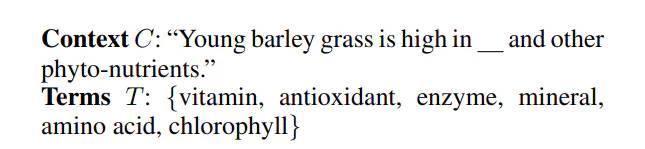
其中 C为句子文本,"__"为替代文本中seed term(s)的占位符,T表示潜在与占位符同级的下义词(hyponym)集合,任务的目标即为找到除s外的语义词,即训练目标如下:
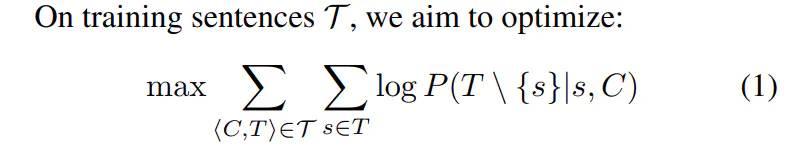
表示为,在输入句子文本C与种子词s条件下,求除种子词的其他词最大概率。下图为模型的整体框架。
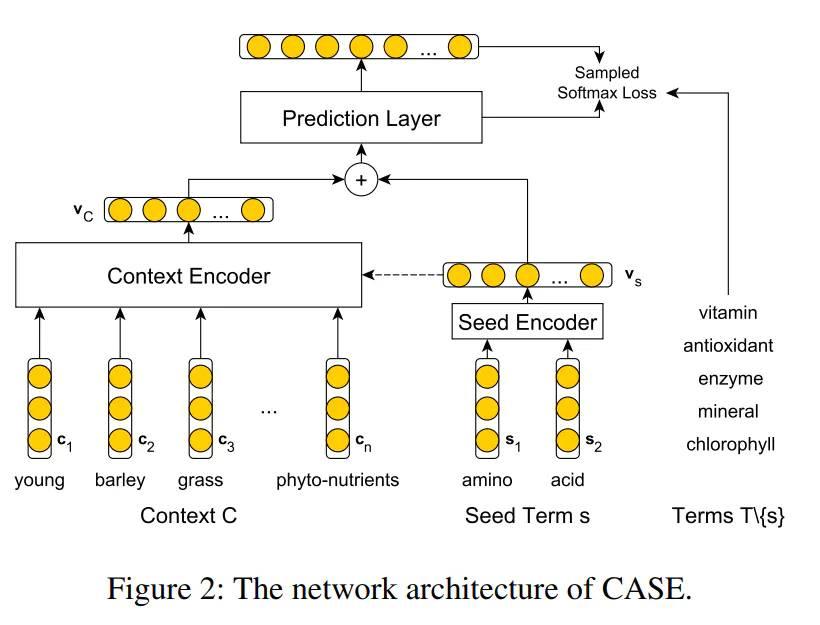
从模型图可以看出,主要分三个部分:Context Encoder、Seed Encoder、Prediction Layer,下面简单介绍下这三个模块。
文中作者提出四种编码方法,第一种为Neural Bag-of-Words Encoder,该方法是利用N-gram的思路,通过looksup词表的方式,得到句子的所有词向量,然后以纵向相加求平均得到句子向量; 第二,三种分布为RNN-Based Encoders 、 CNN-Based Encoders,通过两种编码网络得到句子向量;第四种为Position-Aware Encoders,具体采用类似CNN+PF的方式,将位置信息也嵌入进行学习。最后,通过Context Encoder得到句子向量V_C。
关于句子中Seed Term的编码,文章同样是采用Neural Bag-of-Words Encoder,因为Seed Term有可能是由多个word组成的,所以得到的向量V_S如下:
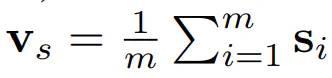
模型的第三部分就是预测扩充的词条,Predicting Expansion Terms,具体为想将上述两个编码层得到的两个向量 concatenation方式得到最终向量x,然后输入softmax层进行预测:
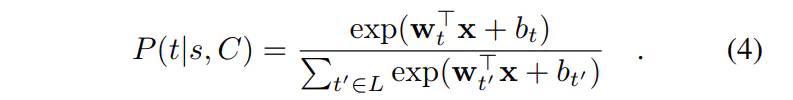
在实际中,相似的语义词有可能很多,而softmax正常只是输出概率最大的一个。文中为了缓解该问题,作者采用sampled softmax loss的方式,实现multi-label的方式进行预测,这样可以大大提高预测效率。
此外,文中在Context Encoder部分还尝试了Attention机制,并提出两种结合方式,一种为Seed-Oblivious Attention,该方法是将句子每个词学一个权重,然后再加权计算最终句子向量;另中为Seed-Aware Attention,该方法是将句子每个词相对Seed Term学一个权重,这里文中提出DOT与TRANS-DOT两种计算方法,然后再加权计算最终句子向量。此环节详情若有兴趣可查看原文。
在实验部分,文中使用的是WebIsA数据集,该数据集180万的训练集,400万的下位词。实验的最终结果为:
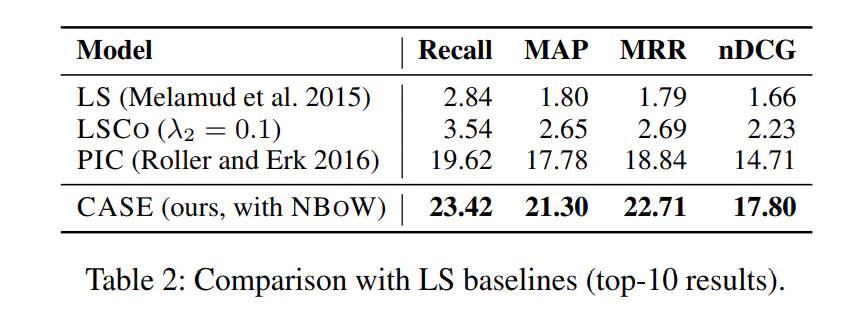
显示相对之前别人的方法,作者的模型在四个评价指标平均有4%的提升,此外作者也验证了前面提到的四种句子编码方式,方法Neural Bag-of-Words Encoder(NBoW)方式效果最好,如下图所示。
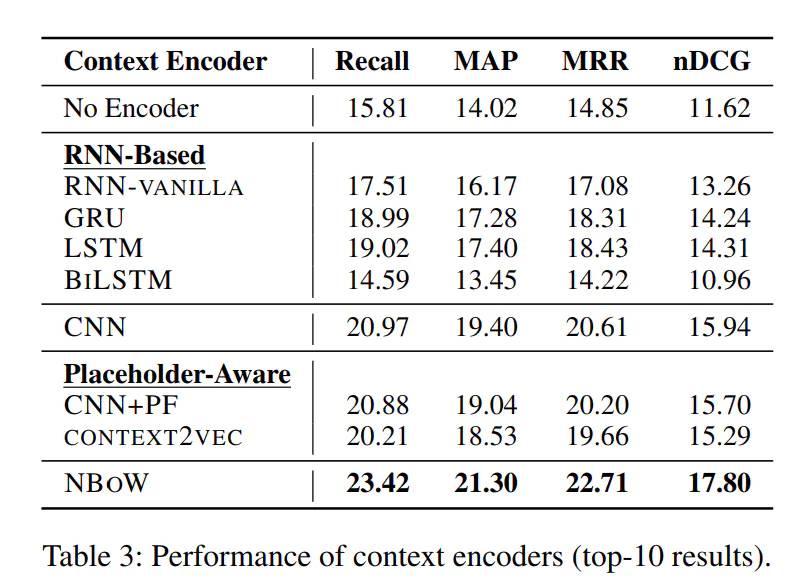
可以看出,多种常规的编码方法效果都没有超过最简单的NBoW方式,这也让我有点惊讶。我想该任务也挺适合上BERT等预训练模型的,因为BERT就是基于上下文进行编码的,不过文中并没有对比在预训练模型下的预测效果。
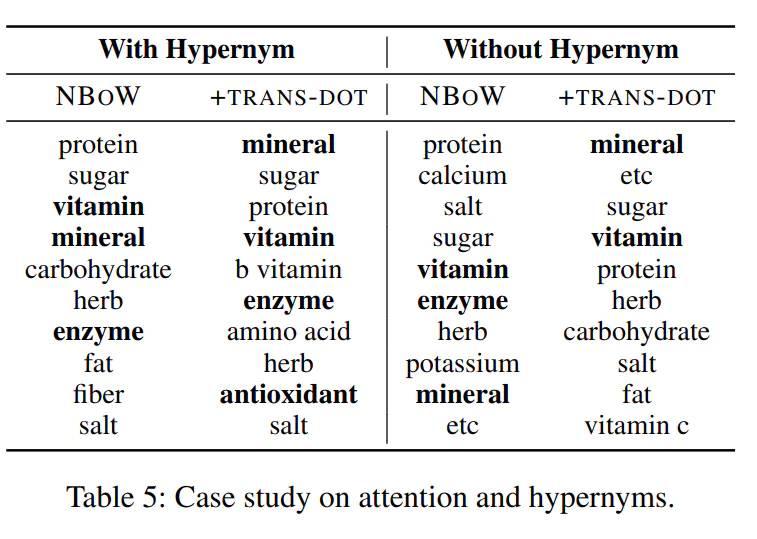
上图是对应前言列举的句子中amino acid(氨基酸)的语义词学到的结果,其中加粗的为扩充的正确相似语义词,其他为扩充的噪声词。左边一列显示在TRANS-DOT注意力机制下,预测的噪声词fat从top10之列移除了,并且有效词得到提升,说明了该方法的有效性。此外,两列一起验证了是否考虑下位词(Hypernym)的效果,结果来看,使用下位词效果稍微好一点,但影响并不大。
从paper解决的任务来看,觉得还是挺有意思,它可视为挖掘近义词或同义词的更细粒度的任务,它考虑了词的语义环境。从实验结果来看,该任务的预测难度还很大,top10的召回率也只有23%左右的效果,说明离实际应用还是有点距离;从Table5显示的结果来看,若不考虑语义环境,只作为近义词的扩充,其实效果还是很不错的。尽管文中提出的方法很简单,但还是被2020年的AAAI会议接受,所以也启发我们,做学术不用太追求模型,方法,踏踏实实把实验做好,做的更落地些,也是能被人青睐,而这篇就具备这样的特点。
此外,我个人觉得该方向作为学术点还是可以继续优化下去的,在如何深入考虑上下文信息上还是有不少可尝试的方法。如果有兴趣的朋友,可以私下交流,也可以尝试合作~~
更多文章可关注笔者公众号:自然语言处理算法与实践
地址:海南省海口市电话:0898-08980898传真:0898-1230-5678
Copyright © 2012-2018 耀世娱乐-耀世注册登录入口 版权所有ICP备案编号:琼ICP备xxxxxxxx号

