



添加时间:2024-05-26 09:29:13
神经网络优化器,主要是为了优化我们的神经网络,使他在我们的训练过程中快起来,节省社交网络训练的时间。在pytorch中提供了方法优化我们的神经网络,是实现各种优化算法的包。最常用的方法都已经支持,接口很常规,所以以后也可以很容易地集成更复杂的方法。
要使用,您必须构造一个optimizer对象。这个对象能保存当前的参数状态并且基于计算梯度更新参数。
要构造一个Optimizer,你必须给它一个包含参数(必须都是Variable对象)进行优化。然后,您可以指定optimizer的参 数选项,比如学习率,权重衰减等。具体参考torch.optim中文文档
这里主要参考加速神经网络训练 (Speed Up Training)教程比喻出来方便大家学习,如果想知道更加详细以及官方的解答,可以参考各种优化方法总结比较(sgd/momentum/Nesterov/adagrad/adadelta)
SGD是最基础的优化方法,普通的训练方法, 需要重复不断的把整套数据放入神经网络NN中训练, 这样消耗的计算资源会很大.当我们使用SGD会把数据拆分后再分批不断放入 NN 中计算. 每次使用批数据, 虽然不能反映整体数据的情况, 不过却很大程度上加速了 NN 的训练过程, 而且也不会丢失太多准确率.
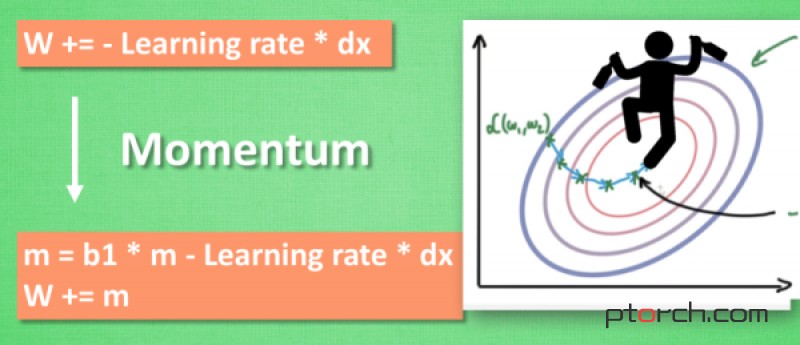
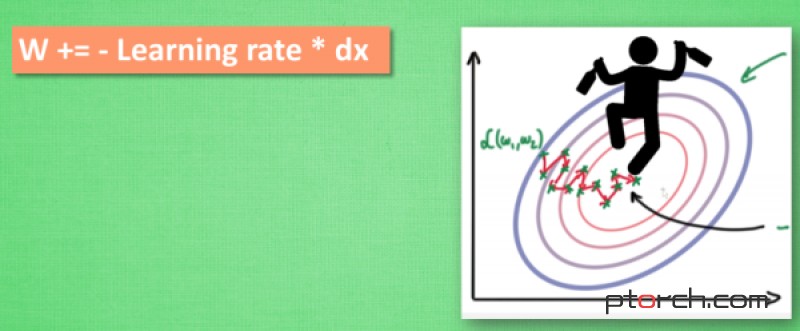 所以我们把这个人从平地上放到了一个斜坡上, 只要他往下坡的方向走一点点, 由于向下的惯性, 他不自觉地就一直往下走, 走的弯路也变少了. 这就是 Momentum 参数更新。
所以我们把这个人从平地上放到了一个斜坡上, 只要他往下坡的方向走一点点, 由于向下的惯性, 他不自觉地就一直往下走, 走的弯路也变少了. 这就是 Momentum 参数更新。

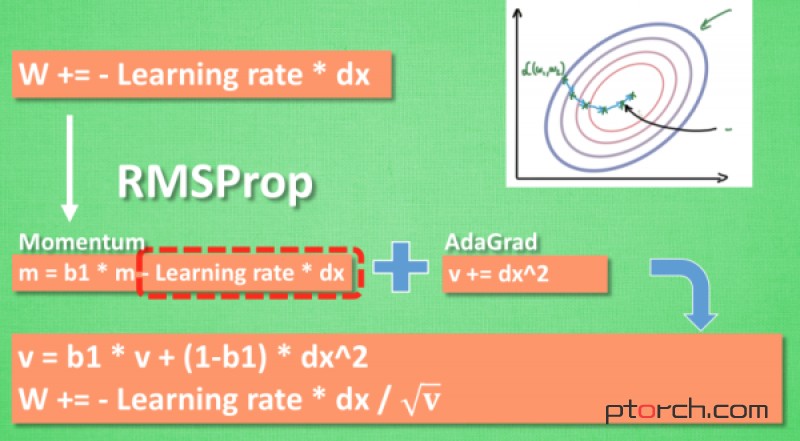
有了 momentum 的惯性原则 , 加上 adagrad 的对错误方向的阻力, 我们就能合并成这样. 让 RMSProp同时具备他们两种方法的优势. 不过细心的同学们肯定看出来了, 似乎在 RMSProp 中少了些什么. 原来是我们还没把 Momentum合并完全, RMSProp 还缺少了 momentum 中的 这一部分. 所以, 我们在 Adam 方法中补上了这种想法.
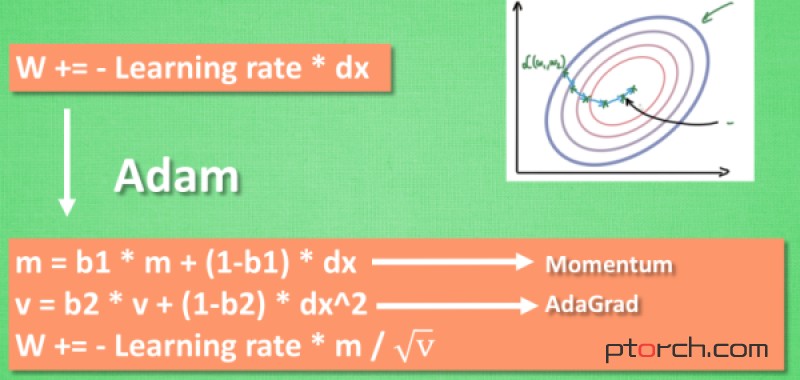
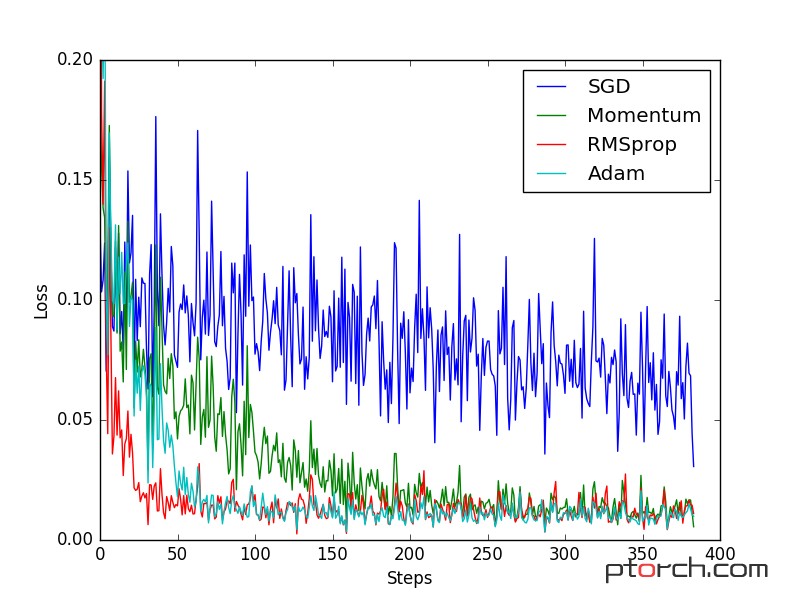
SGD 是最普通的优化器, 也可以说没有加速效果, 而 Momentum 是 SGD 的改良版, 它加入了动量原则. 后面的 RMSprop 又是 Momentum 的升级版. 而 Adam 又是 RMSprop 的升级版. 不过从这个结果中我们看到, Adam 的效果似乎比 RMSprop 要差一点. 所以说并不是越先进的优化器, 结果越佳. 我们在自己的试验中可以尝试不同的优化器, 找到那个最适合你数据/网络的优化器。如果你要查看视频教程Optimizer 优化器
地址:海南省海口市电话:0898-08980898传真:0898-1230-5678
Copyright © 2012-2018 耀世娱乐-耀世注册登录入口 版权所有ICP备案编号:琼ICP备xxxxxxxx号

